

Meta Debuts The Latest AI...
Meta is determined to keep pace with competitors in the field of generative artificial intelligence […]

Adobe Launches Firefly Services –...
Adobe today unveiled its latest offering, Firefly Services, a robust collection of more than 20 […]

Researchers Present An Improved Machine...
A team from Carnegie Mellon University and Los Alamos National Laboratory used the power of […]

Creating A Sense Of Virtual...
Scientists have invented a technology that simulates walking for people who are sitting, dynamically creating […]

Google Temporarily Halts AI Image...
Google has announced that it is temporarily halting the creation of images with images of […]
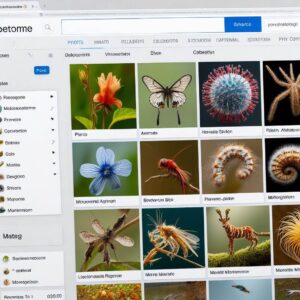
The AI System Uses a...
Scientists have created the most comprehensive collection of images of life forms ever collected for […]

An Innovative Machine Learning Approach...
Researchers at the Tokyo Institute of Technology have developed a machine learning (ML) model that […]

Bridging the Human-Computer Communication Gap
The revolution in user experience driven by advances in natural language processing (NLP) is fundamentally […]

Fighting Forest Fires With Swarms...
Scientists at the Indian Institute of Science are investigating the use of drone clusters to […]

Machine Learning in Telecommunications
The world of telecommunications is at the heart of the digital age, enabling billions of […]

The Role Of Machine Learning...
Industrial operations often depend on the reliable operation of machinery and equipment. Unexpected outages not […]

How Machine Learning Affects The...
Machine learning serves as an intricately woven network of intelligence that underlies the multifaceted operations […]

Game Theory and Machine Learning
The fundamentals of game theory and machine learning form a crucial point in the quest […]

Understanding Efficient Computing
Performance computing is an intriguing field at the intersection of computer science, psychology, and cognitive […]
Time Series Analysis and Machine...
Time series analysis is the analysis of data collected at regular intervals. Consider taking your […]
Comparison of Traditional Regression With...
In the field of data analysis and forecasting, two methodologies stand out for their different […]

Implementing Machine Learning Algorithms with...
Understanding machine learning frameworks and libraries is paramount for any developer or data scientist delving […]

Adaptive Learning
Adaptive learning is a modern educational miracle that embodies the most modern teaching methods. Such […]